A Look at: Okta Api
This post is a musing on the Okta API, how it is structured, what I like and dislike about it, and some decisions to consider when designing your own API.
What is Okta? It’s an identity management system. Or maybe IAM is a better descriptor. Or authentication & authorization service. I’m not great at all these terms and labels; they’re always going to miss something critical about the service and lead to slightly different impressions for different people, anyhow.
If you like comparisons, it’s similar to Azure AD, AWS Cognito, Auth0, OneLogin, Ping Identity, etc. Firebase maybe?? I’ve never used it.
If you like lists, Okta has (among many other things):
- User account storage, with custom attributes & schemas
- Group management capabilities
- OAuth 2 & OIDC integration for SSO capabilities
- Identity Provider support, for inbound SSO
- Workflow extensions for custom behaviors
- Authorization server customization and control
And probably a lot more that I’m not familiar with. It’s an enterprise service, so they cater to a lot of types of customers. I probably butchered this, but hopefully you get the idea.
I have been using Okta in my professional job for the past several months or so. We use it for storing our userbase, and for providing central account management for the various applications our company produces. I’ve come to have some opinions on it, hence this post. There’s a lot of nice things, and a lot of quirks.
Separation of Controlled & Modifiable Data
Okay so this is probably the main reason I want to write this post. I think it makes so much sense, and want to employ it in anything new I write that I can have control over.
When you’re writing a system, there’s a total mix of data objects or collections of data stored in various places and forms.
- Data transfer objects (DTOs) for in-flight requests and responses between systems
- A single database record flattened out
- A group of database records related to each other for one resource
- Object storage (think JSON blob) with various schemas and forms
- Opaque ORM object storage
- Retrieving and storing objects in another API integration
But let’s just look at a single database record for now. Let’s say you’re designing a system, and a particular resource that’s available via API needs to persist. That resource is going to have data like its identifier, its name, when it was created/updated (and by who). Whether it’s been soft-deleted, whether its locked down for editing, and then all of its editable characteristics.
Great! Slap them all in their own columns in the same table. And make a struct to represent them when talking to your database. For instance.
type User struct {
ID string `dynamodbav:"id"`
Created time.Time `dynamodbav:"created"`
CreatedBy time.Time `dynamodbav:"created_by"`
IsAdmin bool `dynamodbav:"is_admin"`
IsDeleted bool `dynamodbav:"is_deleted"`
IsEditable bool `dynamodbav:"is_editable"`
Name string `dynamodbav:"name"`
Email string `dynamodbav:"email"`
Phone string `dynamodbav:"phone"`
}
And we want some simple CRUD operations on this with an API. Create a new User, retrieve user details, edit its properties, delete the user. The user can edit their own name, email, and phone if it’s not locked. But administrators can edit anything, even when locked.
Well, we already have the struct from the database, so we can add some JSON tags or make a new DTO that copies data over for a bit better JSON representation (perhaps with enumerations or other friendly types). Expose that over the API and you’re set. But, there’s some annoying complications with that if you want to be careful.
Should we show the IsEditable field to non-admins?
Are you accidentally allowing a user to include the IsEditable or IsAdmin in their PUT request to edit these otherwise off-limits fields?
Do you have a long string of if statements checking for only certain fields changing and which to update, and might you be forgetting to update that when new fields get added?
Are you white-listing editable fields or blacklisting them on the DTO before changing your database record?
What if the user PUTs to /api/user/:id but includes the id in the JSON body as well?
There’s a lot of considerations when you have such a…flat DTO. All the fields are there right next to each other for POST, PUT, and GET requests/responses. Perhaps we can break it out a bit, maybe with a “metadata” section that you’ve seen elsewhere?
{
"name": "James Linnell",
"email": "james.n.linnell@gmail.com",
"phone": "sike",
"meta": {
"id": "1234",
"created": "2023-07-08T10:44:12-07:00",
"created_by": "5678",
"is_admin": false,
"is_deleted": false,
"is_editable": true
}
}
Your code might be a bit better about separating the editable fields from fields that should be controlled by business logic. The code would provide metadata when fulfilling a GET response, or a response to a POST or PUT. That seems more secure and easier to deal with! This is what I see in, for instance, SCIM.
But I still don’t like it.
Your standardized metadata is only an inclusion on the ever-changing profile of the user object.
And you still have the possibility of a PUT or POST request including the meta object, which shouldn’t be there on writes.
Read-only data would be nicer to not be includable in writes.
Do you ignore it, or error out?
Let’s inverse it! And jump from a contrived example to Okta’s user objects.
{
"id": "00ub0oNGTSWTBKOLGLNR",
"status": "ACTIVE",
"created": "2013-06-24T16:39:18.000Z",
"activated": "2013-06-24T16:39:19.000Z",
"statusChanged": "2013-06-24T16:39:19.000Z",
"lastLogin": "2013-06-24T17:39:19.000Z",
"lastUpdated": "2013-06-27T16:35:28.000Z",
"passwordChanged": "2013-06-24T16:39:19.000Z",
"type": {
"id": "otyfnjfba4ye7pgjB0g4"
},
"profile": {
"login": "isaac.brock@example.com",
"firstName": "Isaac",
"lastName": "Brock",
"nickName": "issac",
"displayName": "Isaac Brock",
"email": "isaac.brock@example.com",
"secondEmail": "isaac@example.org",
"profileUrl": "http://www.example.com/profile",
"preferredLanguage": "en-US",
...
},
"credentials": {
"password": {},
"recovery_question": {
"question": "Who's a major player in the cowboy scene?"
},
"provider": {
"type": "OKTA",
"name": "OKTA"
}
},
"_links": {
"resetPassword": {
"href": "https://{yourOktaDomain}/api/v1/users/00ub0oNGTSWTBKOLGLNR/lifecycle/reset_password"
},
...
}
}
The profile is its own, editable section ✅
The metadata is at the top-level, and read-only ✅
There’s other editable sections separate from the profile, if you want to design that separation ✅
You can provide other metadata sections, like _links ✅
And lets take a brief look at what the HTTP REST API for Okta User resources look like, as well.
POST /api/v1/users
Content-Type: application/json
{
"profile": { ... },
"credentials": { ... }
}
GET /api/v1/users/1234
Content-Type: application/json
200 OK
{
"id": "1234",
...
"profile": { ... },
"credentials": { ... },
"_links": { ... }
}
PUT /api/v1/users/1234
Content-Type: application/json
"profile": { ... }
POST /api/v1/users/1234/lifecycle/deactivate
Content-Type: application/json
200 OK
{
"id": "1234",
"status": "DEPROVISIONED",
"profile": { ... },
"credentials": { ... },
"_links": { ... }
}
DELETE /api/v1/users/1234
Content-Type: application/json
204 No Content
POST /api/v1/users/1234/credentials/change_password
Content-Type: application/json
{
"oldPassword": {
"value": "hunter2"
},
"newPassword": {
"value": "hunter3"
},
"revokeSessions": true
}
200 OK (credentials object)
{
"password": {},
"recovery_question": {
"question": "Who's a major player in the cowboy scene?"
},
"provider": {
"type": "OKTA",
"name": "OKTA"
}
}
That’s a lot. But out metadata is now at the top-level of the API, and the profile attributes are nicely grouped up together by itself at the lower level. And we can add other user-specific sections of data next to the profile attributes! The entire top-level is mainly read-only, so you’ll never have to worry about parsing or ignoring parts of a large object of data just to change one item, such as the user status enumeration. The lifecycle operations are also their own POST endpoints to further keep the mutation of status and the actual JSON read-only representation separated.
This all seems pretty obvious now, especially if you’ve worked with APIs like this before. But designing something from the ground up without a lot of prior experience, I think it’s pretty easy to fall into the “one large flat list of fields” dynamic. Naturally falling into this level of organization takes a lot of iterations and learning from pain points.
I like it, though. It’s a simple, but very effective method to keeping a professional organization of data points for a REST API. And it lets you re-use your DTOs efficiently, without making tons of endpoints and small, mixed DTOs for every operation you can think of. Because we all don’t like duplicated structs and converting between them all the time.
Keep your business-logic read-only data at the top level, and make re-usable DTOs for for read-write data as children! Simple and easy rule-of-thumb to follow for your APIs.
POST Operations
As we saw above, POSTing to operations on Okta API objects/resources is pretty widespread.
POST /api/v1/users/${userId}/lifecycle/activate
POST /api/v1/users/${userId}/credentials/forgot_password
POST /api/v1/authorizationServers/${authorizationServerId}/policies/${policyId}/rules/${ruleId}/lifecycle/deactivate
POST /api/v1/apps/${applicationId}/credentials/secrets/{secretId}/lifecycle/activate
...
I’m not sure how very REST-like this is. However, operations that are disceretely defined and enumerated with clear business rules and flowcharts are nice. I like this a lot better than having a weird mix of data parameters that you try to mutate, and mix together, and potentially get cryptic errors if you mix them the wrong way or do things out of order.
When coding such a thing, I think it also lets you separate a lot of this out into discrete functions as well. Who likes having one large edit/update function that tkaes into consideration every mutation of a large DTO with business rules all over the place? That smells like a recipe for disaster.
I don’t know. I just like it as an easy extension of regular ol' CRUD operations. CRUD can’t account for all of the things you want, when you have to protect items and datapoints with business rules.
Documentation
Okta’s API documentation is…good, but could be better.
They have Postman collections for their ~20 or so sections of API (one for each type of resource, it seems). And they’re mostly complete which is nice. I have my own gripes about Postman collections though.
Scopes
Perhaps my largest pet-peeve is Okta scopes for OAuth-based API access.
They list them out at https://developer.okta.com/docs/api/oauth2/, but it’s not alongside each endpoint.
If I want to be able to know which scope is needed to list out authorization servers, is okta.authenticators.read all I need?
That sounds like a single object, so maybe okta.authorizationServers.manage is better?
Even though that sounds more like editing objects, which maybe I don’t want to do.
A quick tag of which scope(s) are needed per-API endpoint would be a simple and quick quality of life improvement.
Request Parameters
It’d also be nice if there was some separation of request body parameters and url/query parameters. It can be a bit weird to see them all in the same table, like the below.
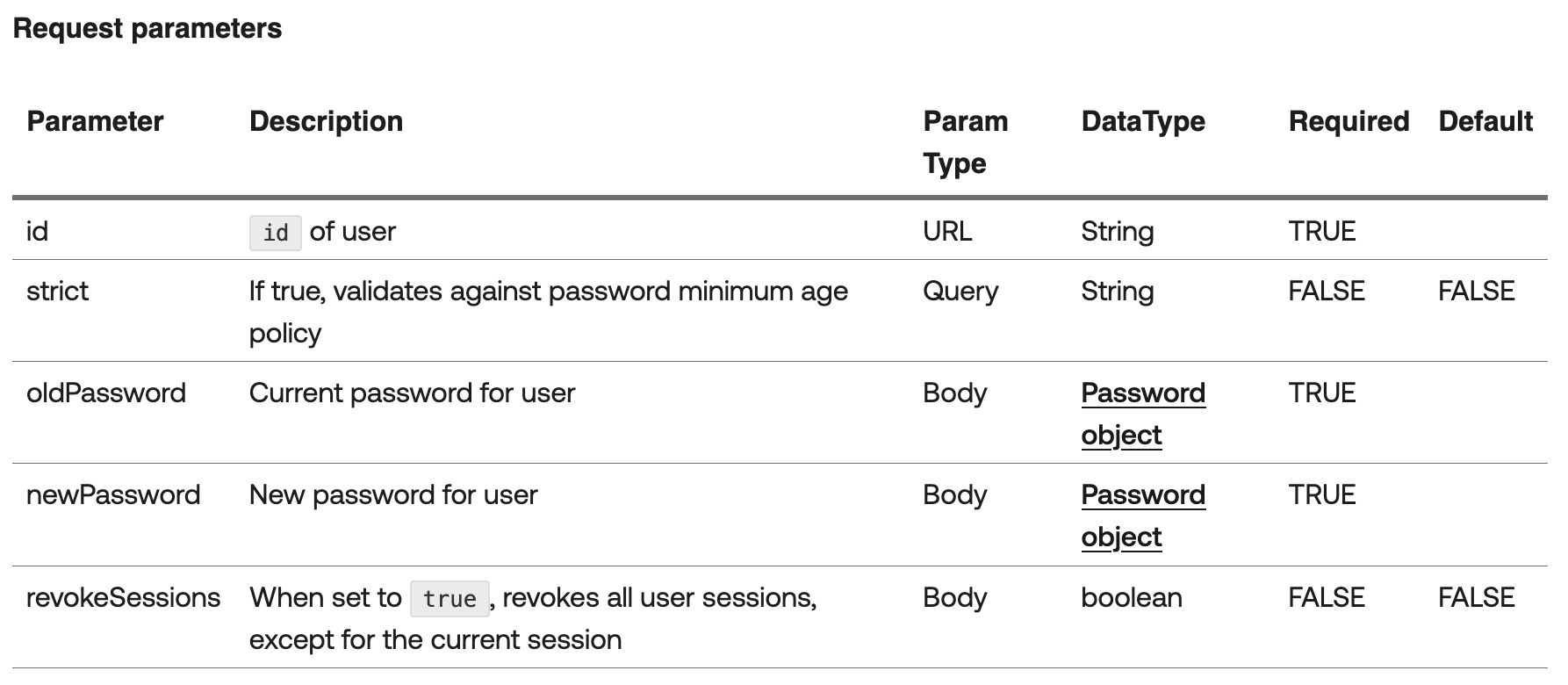
Okta User Change Password Request Parameters
OpenAPI
I’m a fan of OpenAPI. It’d be nice if Okta provided a specification document for their APIs. It’s nice for code generation in a way that Postman collections aren’t good for. But documentation generation from OpenAPI documents isn’t the most flexible, when you don’t have control over separate pages easily. So I get why they don’t bother with that.
But overall, I really do like their documentation. It’s a bit funny with the separation of administrator-type management, and OAuth APIs and their own customizations and such, but it works well.
I like that there’s big sections for each major portion of resources. I like that within a resource, comparable operations are grouped. I like that API-wide items have their own pages, such as rate limiting or pagination (which is standardized 🙏).
Go SDK
Their Go SDK is another thing.
I think that the main gripe I have is that request query parameters are too open and free.
They enumerate the available params, but it’s global for the whole API.
Do you use search or filter for this one endpoint? Well, look at the docs to make sure.
Code/type- restricted availability of each parameter per-endpoint would be nice.
But they provide built-in pagination and rate-limiting functionality! Gotta love that.
Quirk: 404 Not Found
Okay so you know how if you delete a REST resource and you get GETting it later and it gives you a 404 Not Found? We love that about REST APIs.
I think Okta went a bit too far.
GET /api/v1/users/1234
Content-Type: application/json
200 OK
{
"id": "1234",
"status": "ACTIVE",
...
"profile": { ... },
"credentials": { ... },
"_links": { ... }
}
POST /api/v1/users/1234/lifecycle/deactivate
Content-Type: application/json
200 OK
{
"id": "1234",
"status": "DEPROVISIONED",
...
"profile": { ... },
"credentials": { ... },
"_links": { ... }
}
POST /api/v1/users/1234/lifecycle/deactivate (again)
Content-Type: application/json
404 Not Found
{
...
}
I didn’t DELETE the user. Why is the user suddenly “not found” for some operations? I don’t remember if a GET responds with a 404 as well or not, but I’d rather inactive objects still appear in the API layer for other operations. And perhaps give errors for modifying them when you shouldn’t be.
I think that a query for listing all users also doesn’t provide deprovisioned users:
List all Users
Returns a list of all users that do not have a status of DEPROVISIONED, up to the maximum (200 for most orgs)
But perhaps actual queries still return deprovisioned users. But why can a search work and not a direct GET?? Why does an activation work but a double-deactivation report a 404 instead of some kind of “already deactivated” error?
Quirk: Eventual Consistency
This one is small. You create a user and then immediately GET the resource. It works!
You create a user and then immediately query for it, perhaps by the ID or email address. It doesn’t work!
Eventual consistency with a replicated database is a smart move to keep latencies down. Asynchronicity is good for scale. Etc. etc. But when you’re providing an API layer of your own on top of Okta’s API (SCIM, in my case), it can be a bit troublesome. Azure AD as a SCIM client likes to get a GET by searching by a custom identifier, which requires me to always use a query, which is eventually consistent. When the Azure SCIM Validator yells at me for a created resource 404’ing, it’s not fun. I think I just added a small time delay. Okta was nice enough to report that their replication is typically 1 second, so it’s not too bad.
Closing
Overall, I like Okta’s API. Response are a bit slow. But they’ve put a lot of thought into it, and it’s a very good candidate to learn from when designing your own REST API. I just hope I didn’t miss anything obvious! There’s probably a lot of other things that I’m just taking for granted at this point.